The Pros and Cons of Open Data




Melissa Edmiston, Stephanie Coker, Stephanie Jamilla, Thembelihle Tshabalala
Open data is an increasingly important topic in MERL. Many MERL practitioners advocate for open data given the benefits of sharing data that others can use to analyze, reanalyze and draw new and beneficial conclusions. However, making data open does not come without risks and could result in unintended consequences. The following guide outlines some of the pros and cons of open data and things to consider when making your data open. Table 1 includes a summary of key points.
Target Audience: Civil society/NGO professionals, academia, MERL practitioners, end-users of open data, people and researchers interested in creating open data, and/ or funders.
Table 1: Summary of key points
| Pros | Cons |
|---|---|
| Accessibility of data: increased community engagement, improved efficiency and reduced cost, encourages progress and innovation | Incorrect use of data and the problem of missing information |
| Increased transparency | Privacy and consent |
| Reduced corruption | Mosaic effect |
| Interpretation of data | Costs and sustainability of open data projects |
PROS
Accessibility of data
One of the overarching benefits of open data is accessibility. Data collection and cleaning can be expensive, and many projects or organizations are limited in their capacity to collect and manage large amounts of data. Making data open increases the number of datasets available for others to analyze and draw conclusions. This can result in:
Increased community engagement:
Open data has the potential to build a community around the data; bringing people together who are working on similar issues who can exchange ideas, findings and discuss challenges. This can encourage data collaboration rather than competitiveness.
- An example of a community fostered around creating open data is OpenStreetMap (OSM), which is an open-data, volunteer-driven global mapping platform. There is a robust community of OSM data users, as can be seen through the platform’s community blog and users’ diaries, through which users share posts, ask questions, and interact with each other.
- There is also a vibrant community of people who create the spatial data on OSM. Notably there is the MissingMaps project, which is spearheaded by several organizations, aimed at mapping areas prone to disasters and crises. This project has created a global community of mappers all contributing to one goal. For example, one member organization is YouthMappers, whose mission “is to cultivate a generation of young leaders to create resilient communities and to define their world by mapping it.” Over 260 student-led chapters lead mapathons, which are mapping parties, during which participants come together to contribute to a collaborative mapping project on OSM.
Figure 1: Diagram of the Missing Maps Community
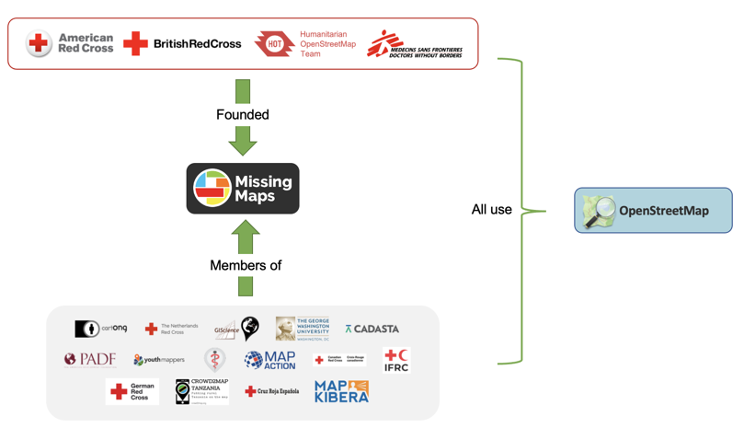
Improved efficiencies and reduced costs:
Access to open data . Open data can be used to enhance data that is already at the disposal of organizations and companies of all sizes, particularly small companies who can benefit from data already available. Open data can also reduce the chance of duplication in data collection efforts, thus saving time and money for organizations. One widely known source of demographic information is Census data, which is accessible and freely available in the United States by visiting data.census.gov. Individuals and organizations can easily tap into this data source in order to save resources otherwise used for primary data collection. For example, one could use Census data instead of designing and implementing their own household survey in the United States. Census data can be used as a baseline for programs as part of monitoring & evaluation, reducing costs for both the program stakeholders and the donor.
Progress and innovation:
Because open data is offered without a monetary barrier, more people have access to it and can explore new methods of analysis, which can further the field of study or contribute to programmatic advancements, encouraging innovation and progress.
- New York City maintains NYC Open Data, a repository of datasets created by various city offices and agencies. Site visitors can access datasets and projects that used the open data. Example projects are a map that shows zoning and building lot data and research on school bullying in NYC. These projects show the potential that open data has in producing important tools and research.
Increased transparency
Open data can also lead to increased transparency. Since open data is freely and publicly available, it lowers the barrier for the general public (and specific stakeholders) to understand the topic or issue the data addresses. Having the data at hand also empowers stakeholders to act on the data, advocating for themselves and their community.
- For example, Mejora Tu Escuela is an open data platform created by the Mexican Institute for Competitiveness that shows information about individual schools’ performance. The goal of the platform is to transform education in Mexico. This data about school performance which previously was unavailable to families and parents, allows them to enroll their children in the schools best for them and to push schools and the government to improve education when their school is lacking in its performance.
Reduced corruption
With increased transparency comes increased accountability and less corruption. This has been accomplished through government anti-corruption/open data policies. Open data strengthens public integrity and accountability between policymakers, government, companies, and citizens through the use of evidence that is generated from open data of either maladministration, governance gaps or blatant corruption. While a significant amount of important and useful government data remains inaccessible, there are examples of governments taking a stance to support open data initiatives.
- According to Transparency International, G20 countries (which make up 20 of the most politically influential and economically powerful countries) have chosen to support open data principles to assist in fighting corruption. For example, South Africa is a founding member of the Open Government Partnership (OGP), a global organization which promotes more open and transparent governments. For open data to be effective in the fight against corruption, it must be published in a timely manner, be accurate, free to use and reuse, and be tangible and analyzable. In South Africa’s case, while there is a commitment to fight corruption through the use of open data, the implementation rate is low, possibly because there are too few open datasets available.
Corruption also tends to group around specific themes that open data must address, such as bribery, corrupt insider fraud, undeclared conflicts of interest and improper use of public funds and lobbying abuses. When these are mapped and linked to sectors, at a minimum, the following datasets should be made open:
Table 2: Open data topics for fighting corruption
| Data Subject | Data Components |
|---|---|
| Political parties | Party budgets, financial and activity reports |
| Parliaments and legislatures | Lobbying activities and parliamentary and administrative data |
| Business and private sector | Company structures, the full name of the company, its unique identifier number, a list of company directors, its statutory filings, and a list of significant shareholders |
| The judiciary | Judges’ contact details, case schedules and court decisions |
| Public officials | Interest and asset declarations, lobbying, procurement processes |
- One example of a government making such datasets openly available is the Brazilian Office of the Comptroller General created the Transparency Portal. The portal is a government tool aimed at increasing fiscal transparency of the Brazilian Federal Government. In this initiative, the Brazilian government published information such as federal agency expenditures, the cost of elected officials to the government’s fiscal budget, and a list of companies banned from doing work for the government. Markdown is a lightweight markup language based on the formatting conventions that people naturally use in email.
Interpretation of data
Open data allows additional individuals to analyze the data and interpret and validate the findings in numerous ways. This reduces the risks that organizations may publish findings or results that used questionable analytical approaches or failed to reveal major biases. A McKinsey report on the benefits of open data stated that open data has three value levers namely: decision making, innovation and accountability. It also highlighted the fact that open data value levers benefit a wide range of stakeholders, and a single open-data initiative has the ability to empower governments, the private sector and NGOs but derive different value depending on the use and the interpretation of the data.
- An example of different stakeholders using the same open dataset to achieve different results is that of a Singaporean initiative about residential energy consumption. They organized a “hackathon”– a community meeting where researchers, sustainability experts, tech start-ups and developers came together to analyze the data and explore ways to create technological interventions to mitigate the impact of increasing energy use. With invitees being from different backgrounds but accessing the same open data, the ability to interpret the data from their own contexts contributed to the creation of apps that helped in decision-making and increasing accountability.
- The interpretation of open data also helps inform consumers. According to the aforementioned McKinsey report, consumer benefit of open data is calculated at $3 trillion in value. A case study in South Africa found that individual interpretation of a medicine price database helped patients save money on medication. Through the use of the Medicine Price Registry application (MPRApp), patients can access information about medications, including their composition and price. Patients can search for cheaper, generic versions of the medication by searching the ingredients and triangulating it through dosage strength information.
CONS/RISK FACTORS
Incorrect use of data and missing data
When using open data, proper consideration of data collection methods and metadata is necessary. When these are misunderstood, erroneous conclusions may be drawn from data.
- For example, an article published by the Institute for Family Studies in 2019 highlighted the results of a study based on the American Time Use Survey (ATUS), an open data survey conducted by the United States Census Bureau. The study claimed that childless single people are happier than married ones. However, this was based on a misunderstanding of how the survey classifies single people and contradicted results from other open data sources.
- Open data can also be incorrectly used when assumptions are made about the representativeness of the population. For example, housing eviction data in the United States only represents formal evictions that go through the court system and may not represent the full picture.
Statistical inferences and data imputation can also present risks when trying to account for missing data. Data can be used or analyzed incorrectly when users don’t pay close attention to the metadata. While the interpretation of data is a positive from an accountability perspective, the negative is that people can also apply open-sourced models or analytical code to datasets incorrectly or misuse or misinterpret the data models.
Privacy and Consent:
Data, whether open or proprietary, is regulated by laws that aim to protect the rights of individuals and guard against malicious use of data. The passage of the EU’s General Data Protection Regulation (GDPR) marked the first enforceable legislation on data privacy. GDPR has been touted as the most significant regulatory development in information policy, influencing the establishment of data privacy policies in other territories. In the United States, the passage of the California Consumer Privacy Act (CCPA) provided similar protections. The Organization for Economic Co-operation and Development (OECD) also provides eight dimensions of data accountability to consider when thinking about privacy protection and transborder flows of personal data. These pieces of legislation and guidelines underscore the importance of consent, and the GDPR specifically requires consent be valid, freely given, specific, informed and active.
Consent should include provisions for users to provide permission for both access and management of their data, as well as the ability to revoke such consent.
- A 2020 study of consent provision options typically offered by large technology companies (Google, Amazon, Facebook, Apple and Microsoft) found several problems with the current frameworks for obtaining consent, concluding they violated principles of fairness, accountability and transparency. Additionally, although a 2015 study found no significant differences in consent provision rates with or without open data policies (suggesting that publishing of open data by itself does not influence consent), consent must be viewed as dynamic and carefully examined at each stage of open data publication.
Attention must be paid to correctly de-identifying and anonymizing data that is collected from individuals. For vulnerable populations, adherence to regulations governing data dissemination is especially critical.
Mosaic Effect
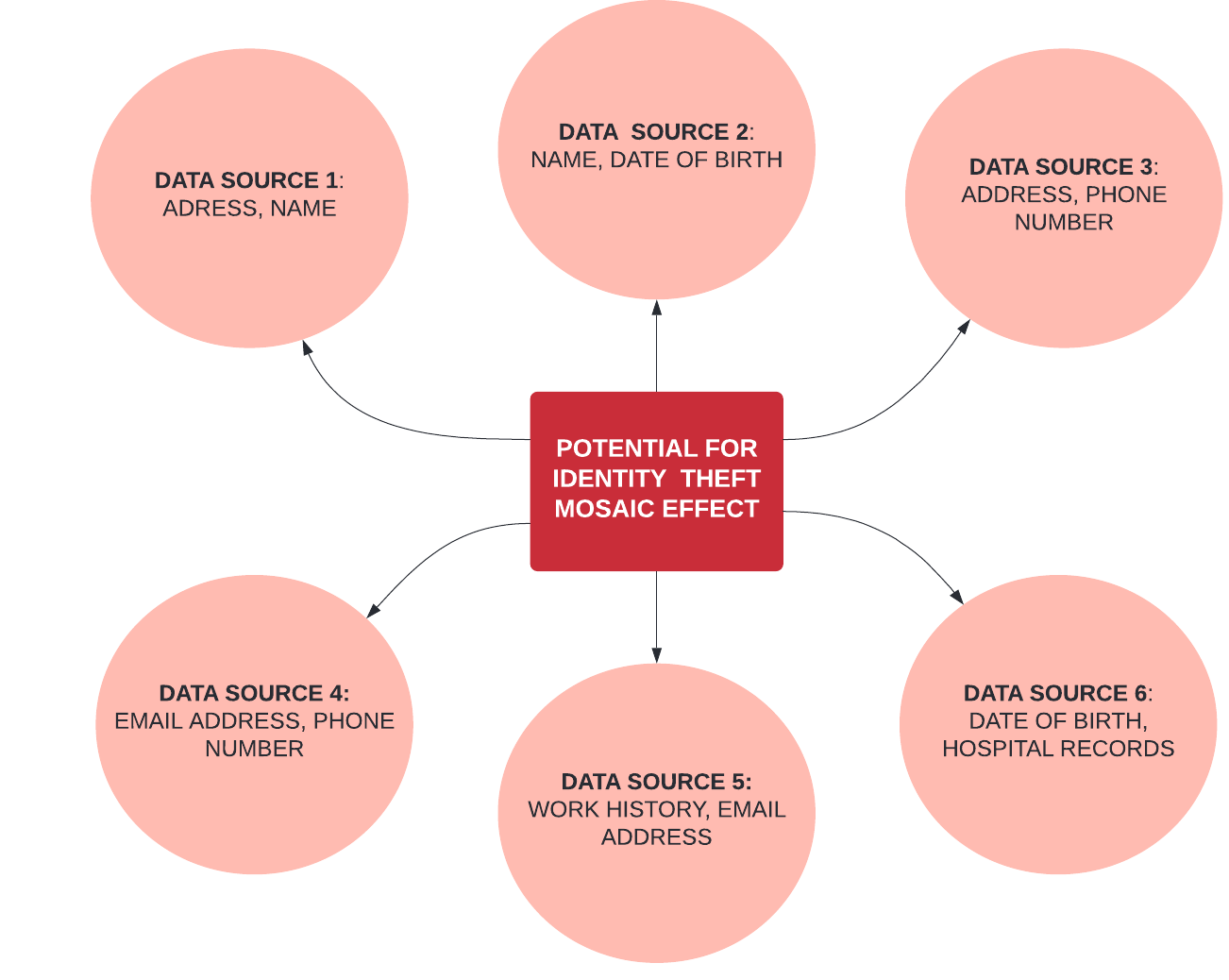
The mosaic effect is a term used when discussing confidentiality. It is derived from the mosaic theory of intelligence gathering, in which disparate pieces of information become significant when combined with other types of information. Applied to data in the MERL sector, this occurs when multiple datasets are linked to reveal new information. Even if data is appropriately anonymized, and efforts are made to remove personal identifiers, if there are multiple datasets containing similar or complementary information, it’s possible to determine identity based on the various data combined across the datasets such as gender, location, educational status, etc. Resources are now available to help MERL practitioners think about how their data may contain certain linkages or risks which may require additional levels of security or anonymization. Figure 2 displays an example of how identity theft can occur when the mosaic effect takes place.
Figure 2: Mosaic Effect Example of Identity Theft
Costs and sustainability of open data projects
Open data has been described as a public good. While the data is offered for free, there is usually a huge cost for the organization implementing the open data initiative. According to recent literature, beginning costs of open data initiatives vary from €20,000 to €100,000 per organization. Startup costs are also followed by adaptation costs, infrastructural costs, and maintenance/operational costs. Costs associated with M&E projects vary widely as well, costing anywhere from 3% to 10% of program budgets. For many NGOs or organizations interested in open data for M&E, these costs are out of range.
Additionally, from an NGO/non-profit perspective, funding these open data projects is also dependent on being able to pitch the usefulness of open data to funders. There is a risk of funders’ priorities changing, which can harm the long-term sustainability of the open data project. Another risk is that if funders’ and users’ agendas don’t align, the open data project may end up not serving the needs of the people who actually use the data. All these sustainability factors affect decision-making around open data initiatives and often end up proving to be insurmountable.
These pros and cons outlined above should be considered and discussed as organizations see to either make their data open or utilize open data collected through other sources. Progress has been made to address some of the challenges, but more work is needed.
Resources and Citations:
- OpenStreetMap - Blogs
- OpenStreetMap - Users’ Diaries
- MissingMaps
- YouthMappers
- Why do we need open data access?
- NYC Open Data
- NYC Open Data - Project Gallery
- NYC Open Data - Context Explorer NYC
- NYC Open Data - What We Learned from Open Data on Bullying and Harassment in NYC Schools
- Mejora Tu Escuela
- Mexico’s Mejora Tu Escuela: Empowering Citizens to Make Data-Driven Decisions about Education
- Open data to fight corruption – Case study: Lithuania’s judiciary (pdf)
- Open data and the fight against corruption in South Africa (pdf)
- Brazil’s Open Budget Transparency Portal: Making Public How Public Money Is Spent
- How Government Can Promote Open Data and Help Unleash Over $3 Trillion in Economic Value (pdf)
- South Africa: Code4SA Cheaper Medicines for Consumers
- MPRApp
- Code for South Africa
- Are Married People Still Happier?
- The European Union general data protection regulation: what it is and what it means
- OECD Guidelines on the Protection of Privacy and Transborder Flows of Personal Data
- A Human-centric Perspective on Digital Consenting: The Case of GAFAM (pdf)
- Impact of Open Data Policies on Consent to Participate in Human Subjects Research: Discrepancies between Participant Action and Reported Concerns
- The Mosaic Theory, National Security, and the Freedom of Information Act
- Governing the Commons: The Evolution of Institutions for Collective Action
- Funding Open Data
- Financing Monitoring & Evaluation: A Self-study Toolkit (pdf)